Releases: JohnSnowLabs/spark-nlp
Spark NLP 5.4.1: Patch release
5a01057🔥 New Features & Enhancements
- Added support for loading duplicate models in Spark NLP, allowing multiple models from the same annotator to be loaded simultaneously.
- Updated the README for better coherence and added new pages to the website.
- Added support for a stop IDs list to halt text generation in Phi, Mistral, and Llama annotators.
🐛 Bug Fixes
- Fixed the default model names for Phi2 and Mistral AI annotators.
📖 Documentation
- Import models from TF Hub & HuggingFace
- Spark NLP Notebooks
- Models Hub with new models
- Spark NLP Articles
- Spark NLP in Action
- Spark NLP Documentation
- Spark NLP Scala APIs
- Spark NLP Python APIs
❤️ Community support
- Slack For live discussion with the Spark NLP community and the team
- GitHub Bug reports, feature requests, and contributions
- Discussions Engage with other community members, share ideas, and show off how you use Spark NLP!
- Medium Spark NLP articles
- YouTube Spark NLP video tutorials
Installation
Python
#PyPI
pip install spark-nlp==5.4.1Spark Packages
spark-nlp on Apache Spark 3.0.x, 3.1.x, 3.2.x, 3.3.x, 3.4.x, and 3.5.x: (Scala 2.12):
spark-shell --packages com.johnsnowlabs.nlp:spark-nlp_2.12:5.4.1
pyspark --packages com.johnsnowlabs.nlp:spark-nlp_2.12:5.4.1GPU
spark-shell --packages com.johnsnowlabs.nlp:spark-nlp-gpu_2.12:5.4.1
pyspark --packages com.johnsnowlabs.nlp:spark-nlp-gpu_2.12:5.4.1Apple Silicon (M1 & M2)
spark-shell --packages com.johnsnowlabs.nlp:spark-nlp-silicon_2.12:5.4.1
pyspark --packages com.johnsnowlabs.nlp:spark-nlp-silicon_2.12:5.4.1AArch64
spark-shell --packages com.johnsnowlabs.nlp:spark-nlp-aarch64_2.12:5.4.1
pyspark --packages com.johnsnowlabs.nlp:spark-nlp-aarch64_2.12:5.4.1Maven
spark-nlp on Apache Spark 3.0.x, 3.1.x, 3.2.x, 3.3.x, 3.4.x, and 3.5.x:
<dependency>
<groupId>com.johnsnowlabs.nlp</groupId>
<artifactId>spark-nlp_2.12</artifactId>
<version>5.4.1</version>
</dependency>spark-nlp-gpu:
<dependency>
<groupId>com.johnsnowlabs.nlp</groupId>
<artifactId>spark-nlp-gpu_2.12</artifactId>
<version>5.4.1</version>
</dependency>spark-nlp-silicon:
<dependency>
<groupId>com.johnsnowlabs.nlp</groupId>
<artifactId>spark-nlp-silicon_2.12</artifactId>
<version>5.4.1</version>
</dependency>spark-nlp-aarch64:
<dependency>
<groupId>com.johnsnowlabs.nlp</groupId>
<artifactId>spark-nlp-aarch64_2.12</artifactId>
<version>5.4.1</version>
</dependency>FAT JARs
-
CPU on Apache Spark 3.0.x/3.1.x/3.2.x/3.3.x/3.4.x/3.5.x: https://s3.amazonaws.com/auxdata.johnsnowlabs.com/public/jars/spark-nlp-assembly-5.4.1.jar
-
GPU on Apache Spark 3.0.x/3.1.x/3.2.x/3.3.x/3.4.x/3.5.x: https://s3.amazonaws.com/auxdata.johnsnowlabs.com/public/jars/spark-nlp-gpu-assembly-5.4.1.jar
-
M1 on Apache Spark 3.0.x/3.1.x/3.2.x/3.3.x/3.4.x/3.5.x: https://s3.amazonaws.com/auxdata.johnsnowlabs.com/public/jars/spark-nlp-silicon-assembly-5.4.1.jar
-
AArch64 on Apache Spark 3.0.x/3.1.x/3.2.x/3.3.x/3.4.x/3.5.x: https://s3.amazonaws.com/auxdata.johnsnowlabs.com/public/jars/spark-nlp-aarch64-assembly-5.4.1.jar
What's Changed
- Fixing default names for Phi2 and MistralAI by @ahmedlone127 in #14338
- [SPARKNLP-1052] Adding random suffix to avoid duplication in spark files by @danilojsl in #14340
- [SPARKNLP-1015] Restructuring Readme and Documentation by @danilojsl in #14341
- Added custom stop token id support by @prabod in #14344
- Update 2023-03-01-t5_flan_base_xx.md by @dcecchini in #14345
- Spark NLP 5.4.1 by @maziyarpanahi in #14350
Full Changelog: 5.4.0...5.4.1
Contributors
Assets 2
Spark NLP 5.4.0: Launching OpenVINO Runtime Integration, Advanced Model Support for LLMs, Enhanced Performance with New Annotators, Improved Cloud Scalability, and Comprehensive Updates Across the Board!
c06d94f📢 It's All About LLMs!
We're excited to share some amazing updates in the latest Spark NLP release of Spark NLP 🚀 5.4.0! This update is packed with new features and improvements that are set to transform natural language processing. One of the highlights is the integration of OpenVINO Runtime, which significantly boosts performance and efficiency across Intel hardware. You can now enjoy up to a 40% increase in performance compared to TensorFlow, with support for various model formats like ONNX, PaddlePaddle, TensorFlow, and TensorFlow Lite.
We've also added some powerful new annotators: BertEmbeddings, RoBertaEmbeddings, and XlmRoBertaEmbeddings. These are specially fine-tuned to take full advantage of the OpenVINO toolkit, offering better model accuracy and speed.
Another big change is in how we distribute models. We've moved from Broadcast to addFile for model distribution, which makes it easier to scale and manage large language models (LLMs) in cloud environments. This is especially helpful for models with over 7 billion parameters.
In addition, we've introduced the Mistral and Phi-2 architectures, optimized for high-efficiency quantization. There are also practical improvements to core components, like enhanced pooling for BERT-based models and updates to the OpenAIEmbeddings annotator for better performance and integration.
We want to thank our community for their valuable feedback, feature requests, and contributions. Our Models Hub now contains over 37,000+ free and truly open-source models & pipelines. 🎉
Spark NLP ❤️ OpenVINO

🔥 New Features & Enhancements

NEW Integration: OpenVINO Runtime for Spark NLP 🚀: We're thrilled to announce the integration of OpenVINO Runtime, enhancing Spark NLP with high-performance inference capabilities. OpenVINO Runtime supports direct reading of models in ONNX, PaddlePaddle, TensorFlow, and TensorFlow Lite formats, enabling out-of-the-box optimizations and superior performance on supported Intel hardware.
Enhanced Model Support and Performance Gains: The integration allows Spark NLP to utilize the OpenVINO Runtime API for Java, facilitating the loading and execution of models across various formats including ONNX, PaddlePaddle, TensorFlow, TensorFlow Lite, and OpenVINO IR. Impressively, benchmarks show up to a 40% performance improvement over TensorFlow with no additional tuning required. Additionally, users can harness the full optimization and quantization capabilities of the OpenVINO toolkit via the Model Conversion API.
Enabled Annotators: This update brings OpenVINO compatibility to a range of Spark NLP annotators, including BertEmbeddings, RoBertaEmbeddings, XlmRoBertaEmbeddings, T5Transformer, E5Embeddings, LLAMA2, Mistral, Phi2, and M2M100.
Acknowledgements: This significant enhancement was accomplished during Google Summer of Code 2023. Special thanks to Rajat Krishna (@rajatkrishna) and the entire OpenVINO team for their invaluable support and collaboration. #14200


- New Mistral Integration: We are excited to introduce the
Mistralintegration, featuring models fine-tuned on theMistralForCasualLMarchitecture. This addition enhances performance and efficiency by supporting quantization in INT4 and INT8 for CPUs via OpenVINO. #14318
 > Performance of Mistral 7B and different Llama models on a wide range of benchmarks. For all metrics, all models were re-evaluated with our evaluation pipeline for accurate comparison. Mistral 7B significantly outperforms Llama 2 13B on all metrics, and is on par with Llama 34B (since Llama 2 34B was not released, we report results on Llama 34B). It is also vastly superior in code and reasoning benchmarks. https://mistral.ai/news/announcing-mistral-7b/
> Performance of Mistral 7B and different Llama models on a wide range of benchmarks. For all metrics, all models were re-evaluated with our evaluation pipeline for accurate comparison. Mistral 7B significantly outperforms Llama 2 13B on all metrics, and is on par with Llama 34B (since Llama 2 34B was not released, we report results on Llama 34B). It is also vastly superior in code and reasoning benchmarks. https://mistral.ai/news/announcing-mistral-7b/
Continuing our commitment to user-friendly and scalable solutions, the integration of the Mistral architecture has been designed to be straightforward and easily adoptable, ensuring that users can leverage these enhancements without complexity:
doc_assembler = DocumentAssembler() \
.setInputCol("text") \
.setOutputCol("document")
mistral = MistralTransformer \
.pretrained() \
.setMaxOutputLength(50) \
.setDoSample(False) \
.setInputCols(["document"]) \
.setOutputCol("mistral_generation")- New Phi-2 Integrations: Introducing
Phi-2, featuring models fine-tuned using thePhiForCausalLMarchitecture. This update enhances OpenVINO's capabilities, enabling quantization in INT4 and INT8 for CPUs to optimize both performance and efficiency. #14318
Continuing our commitment to user-friendly and scalable solutions, the integration of the Phi architecture has been designed to be straightforward and easily adoptable, ensuring that users can leverage these enhancements without complexity:
doc_assembler = DocumentAssembler() \
.setInputCol("text") \
.setOutputCol("document")
phi2 = Phi2Transformer \
.pretrained() \
.setMaxOutputLength(50) \
.setDoSample(False) \
.setInputCols(["document"]) \
.setOutputCol("phi2_generation")- NEW: Enhanced LLM Distribution: We've optimized the scalability of large language models (LLMs) in the cloud by transitioning from Broadcast to
addFilefor deep learning distribution across any cluster. This change addresses the challenges of handling modern LLMs—some boasting over 7 billion parameters—by improving memory management and overcoming serialization limits previously encountered with Java Bytes and Apache Spark's Broadcast method. This update significantly boosts Spark NLP's ability to process LLMs efficiently, underscoring our dedication to delivering scalable NLP solutions.#14236
-
NEW: MPNetForTokenClassification Annotator: Introducing the
MPNetForTokenClassificationannotator in Spark NLP 🚀. This annotator efficiently loads MPNet models equipped with a token classification head (a linear layer atop the hidden-states output), ideal for Named-Entity Recognition (NER) tasks. It supports models trained or fine-tuned in ONNX format usingMPNetForTokenClassificationfor PyTorch orTFCamembertForTokenClassificationfor TensorFlow from HuggingFace 🤗. [View Pull Request](#14322 -
Enhanced Pooling for BERT, RoBERTa, and XLM-RoBERTa: We've added support for average pooling in
BertSentenceEmbeddings,RoBertaSentenceEmbeddings, andXLMRoBertaEmbeddingsannotators. This feature is especially useful when the [CLS] token is not fine-tuned for sentence embeddings via average pooling. View Pull Request -
Refined OpenAIEmbeddings: Upgraded to support escape characters to prevent JSON content issues, changed the output annotator type from
DOCUMENTtoSENTENCE_EMBEDDINGS(note: this affects backward compatibility), enhanced output embeddings with metadata from the document column, introduced a Python unit test class, and added a new submodule for reliable saving/loading of the annotator. View Pull Request -
New OpenVINO Notebooks: Released notebooks for exporting HuggingFace models using Optimum Intel and importing into Spark NLP. This update includes notebooks for
BertEmbeddings,E5Embeddings,LLAMA2Transformer,RoBertaEmbeddings,XlmRoBertaEmbeddings, andT5Transformer. View Pull Request
🐛 Bug Fixes
- Resolved Connection Timeout Issue: Fixed the
Timeout waiting for connection from poolerror that occurred when downloading multiple models simultaneously. View Pull Request - Corrected Llama-2 Decoder Position ID: Addressed an issue where the Llama-2 decoder received an incorrect next position ID. View Pull Request
- Stabilized BertForZeroShotClassification: Fixed crashes in sentence-wise pipelines by implementing a method to pad all required arrays within a batch to the same length. View Pull Request
- Updated Transformers Dependency: Resolved the import issue with
keras.engineby updating the transformers version to4.34.1. View Pull Request - ONNX Model Version Compatibility: Fixed
Unsupported model IR version: 10, max supported IR version: 9by setting the ONNX version toonnx==1.14.0. View Pull Request - Resolved Breeze Compatibility Issue: Addressed
java.lang.NoSuchMethodErrorby ensuring compatibility with Spark 3.4 and updating documentation accordingly. [View Pull Request](https://github.com/Jo...
Spark NLP 5.3.3: Patch release
🔥 New Features & Enhancements
- NEW: Introducing
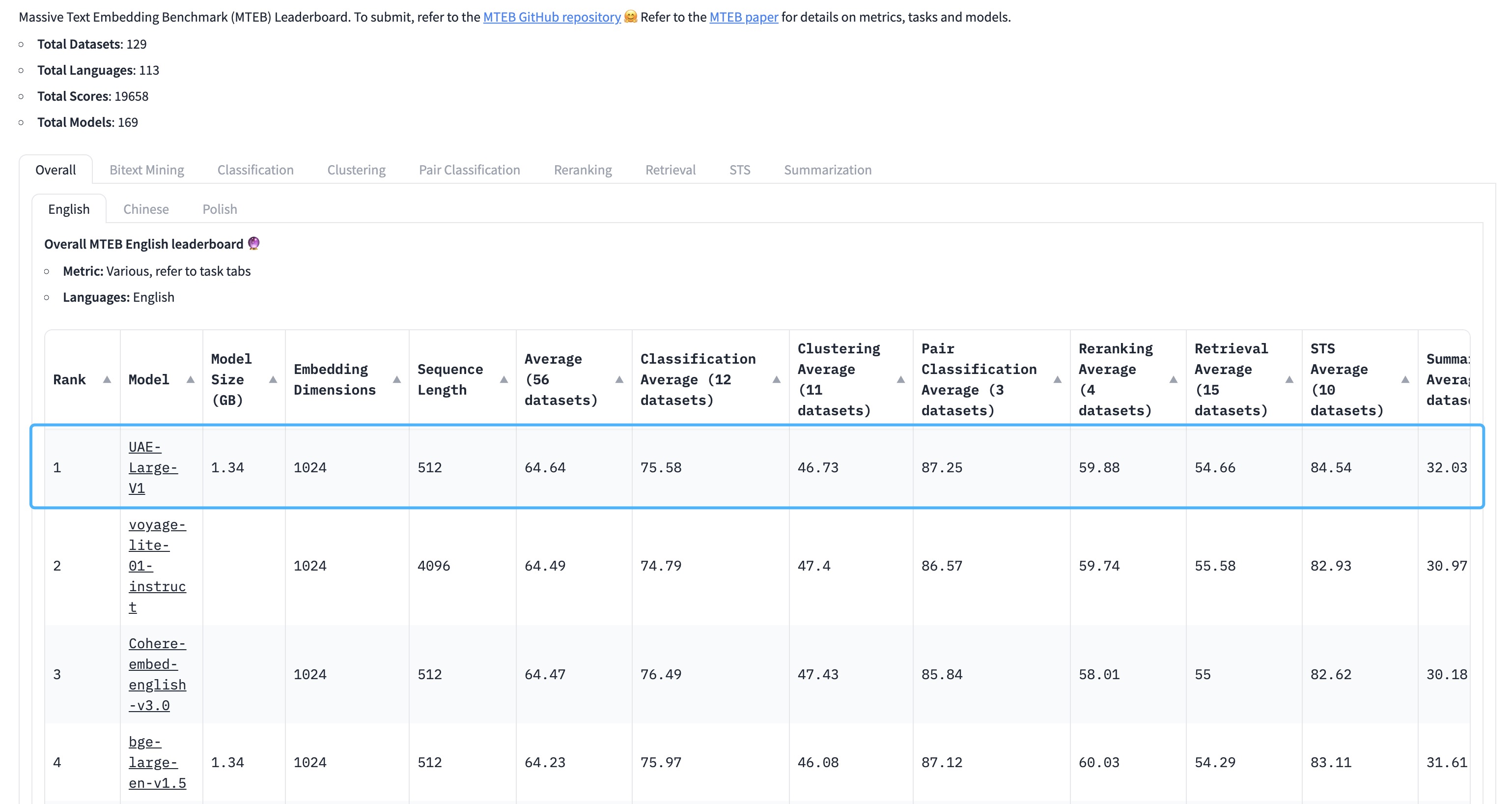
UAEEmbeddingsfor sentence embeddings using Universal AnglE Embedding, aimed at improving semantic textual similarity tasks.
UAE is a novel angle-optimized text embedding model, designed to improve semantic textual similarity tasks, which are crucial for Large Language Model (LLM) applications. By introducing angle optimization in a complex space, AnglE effectively mitigates saturation of the cosine similarity function. https://arxiv.org/pdf/2309.12871.pdf
🔥 The universal English sentence embedding WhereIsAI/UAE-Large-V1 achieves SOTA on the MTEB Leaderboard with an average score of 64.64!
- Introduce critical enhancements and optimizations to the processing of the CoNLL-U format for Dependency Parsers training, including enhanced multiword token handling and improved handling of missing uPos values
- Implement cache mechanism for
metadata.json, enhancing efficiency by avoiding unnecessary downloads - Add example notebook for
DocumentCharacterTextSplitter - Add example notebook for
DeBertaForZeroShotClassification - Add example notebooks for
BGEEmbeddingsandMPNetEmbeddings - Add example notebook for
MPNetForQuestionAnswering - Add example notebook for
MPNetForSequenceClassification
🐛 Bug Fixes
- Address a bug with serializing ONNX models that lack a
.onnx_datafile, ensuring better reliability in model serialization processes - Delete redundant
Multilingual_Translation_with_M2M100.ipynbnotebook entries - Fix Colab link for the M2M100 notebook
📖 Documentation
- Import models from TF Hub & HuggingFace
- Spark NLP Notebooks
- Models Hub with new models
- Spark NLP Articles
- Spark NLP in Action
- Spark NLP Documentation
- Spark NLP Scala APIs
- Spark NLP Python APIs
❤️ Community support
- Slack For live discussion with the Spark NLP community and the team
- GitHub Bug reports, feature requests, and contributions
- Discussions Engage with other community members, share ideas, and show off how you use Spark NLP!
- Medium Spark NLP articles
- YouTube Spark NLP video tutorials
Installation
Python
#PyPI
pip install spark-nlp==5.3.3Spark Packages
spark-nlp on Apache Spark 3.0.x, 3.1.x, 3.2.x, 3.3.x, 3.4.x, and 3.5.x: (Scala 2.12):
spark-shell --packages com.johnsnowlabs.nlp:spark-nlp_2.12:5.3.3
pyspark --packages com.johnsnowlabs.nlp:spark-nlp_2.12:5.3.3GPU
spark-shell --packages com.johnsnowlabs.nlp:spark-nlp-gpu_2.12:5.3.3
pyspark --packages com.johnsnowlabs.nlp:spark-nlp-gpu_2.12:5.3.3Apple Silicon (M1 & M2)
spark-shell --packages com.johnsnowlabs.nlp:spark-nlp-silicon_2.12:5.3.3
pyspark --packages com.johnsnowlabs.nlp:spark-nlp-silicon_2.12:5.3.3AArch64
spark-shell --packages com.johnsnowlabs.nlp:spark-nlp-aarch64_2.12:5.3.3
pyspark --packages com.johnsnowlabs.nlp:spark-nlp-aarch64_2.12:5.3.3Maven
spark-nlp on Apache Spark 3.0.x, 3.1.x, 3.2.x, 3.3.x, 3.4.x, and 3.5.x:
<dependency>
<groupId>com.johnsnowlabs.nlp</groupId>
<artifactId>spark-nlp_2.12</artifactId>
<version>5.3.3</version>
</dependency>spark-nlp-gpu:
<dependency>
<groupId>com.johnsnowlabs.nlp</groupId>
<artifactId>spark-nlp-gpu_2.12</artifactId>
<version>5.3.3</version>
</dependency>spark-nlp-silicon:
<dependency>
<groupId>com.johnsnowlabs.nlp</groupId>
<artifactId>spark-nlp-silicon_2.12</artifactId>
<version>5.3.3</version>
</dependency>spark-nlp-aarch64:
<dependency>
<groupId>com.johnsnowlabs.nlp</groupId>
<artifactId>spark-nlp-aarch64_2.12</artifactId>
<version>5.3.3</version>
</dependency>FAT JARs
-
CPU on Apache Spark 3.0.x/3.1.x/3.2.x/3.3.x/3.4.x/3.5.x: https://s3.amazonaws.com/auxdata.johnsnowlabs.com/public/jars/spark-nlp-assembly-5.3.3.jar
-
GPU on Apache Spark 3.0.x/3.1.x/3.2.x/3.3.x/3.4.x/3.5.x: https://s3.amazonaws.com/auxdata.johnsnowlabs.com/public/jars/spark-nlp-gpu-assembly-5.3.3.jar
-
M1 on Apache Spark 3.0.x/3.1.x/3.2.x/3.3.x/3.4.x/3.5.x: https://s3.amazonaws.com/auxdata.johnsnowlabs.com/public/jars/spark-nlp-silicon-assembly-5.3.3.jar
-
AArch64 on Apache Spark 3.0.x/3.1.x/3.2.x/3.3.x/3.4.x/3.5.x: https://s3.amazonaws.com/auxdata.johnsnowlabs.com/public/jars/spark-nlp-aarch64-assembly-5.3.3.jar
What's Changed
- Uploading missing notebooks from Spark NLP v 5.1.4 by @AbdullahMubeenAnwar in #14196
- SPARKNLP-962: UAEEmbeddings by @DevinTDHa in #14199
- Cache mechanism implementation for metadata.json by @mehmetbutgul in #14224
- [SPARKNLP-1031] Solves Dependency Parsers training issue by @danilojsl in #14225
- Models hub by @maziyarpanahi in #14228
- release/533-release-candidate by @maziyarpanahi in #14227
- Models hub by @maziyarpanahi in #14230
Full Changelog: 5.3.2...5.3.3
Spark NLP 5.3.2: Patch release
🐛 Bug Fixes & Enhancements
- Over 40 new interactive
Streamlitdemos #14175 - Fix and add notebooks to import models from Hugging Face #14192
- Add ONNX and TensorFlow notebooks
- Fix XlnetForSeqeunceClassification and added XlnetForTokenClassificaiton
- Rename DistilBertForZeroShotClassification
- Add missing notebooks
- Update documentation for sparknlp.start() #14206
- Add MPNetEmbeddings to annotator #14202
- Fix
XLMRoBertaForQuestionAnswering,XLMRoBertaForTokenClassification, andXLMRoBertaForSequenceClassification: Reverted the change intfFilenaming that was causing exceptions while loading and saving the models #14204
📖 Documentation
- Import models from TF Hub & HuggingFace
- Spark NLP Notebooks
- Models Hub with new models
- Spark NLP Articles
- Spark NLP in Action
- Spark NLP Documentation
- Spark NLP Scala APIs
- Spark NLP Python APIs
❤️ Community support
- Slack For live discussion with the Spark NLP community and the team
- GitHub Bug reports, feature requests, and contributions
- Discussions Engage with other community members, share ideas, and show off how you use Spark NLP!
- Medium Spark NLP articles
- YouTube Spark NLP video tutorials
Installation
Python
#PyPI
pip install spark-nlp==5.3.2Spark Packages
spark-nlp on Apache Spark 3.0.x, 3.1.x, 3.2.x, 3.3.x, 3.4.x, and 3.5.x: (Scala 2.12):
spark-shell --packages com.johnsnowlabs.nlp:spark-nlp_2.12:5.3.2
pyspark --packages com.johnsnowlabs.nlp:spark-nlp_2.12:5.3.2GPU
spark-shell --packages com.johnsnowlabs.nlp:spark-nlp-gpu_2.12:5.3.2
pyspark --packages com.johnsnowlabs.nlp:spark-nlp-gpu_2.12:5.3.2Apple Silicon (M1 & M2)
spark-shell --packages com.johnsnowlabs.nlp:spark-nlp-silicon_2.12:5.3.2
pyspark --packages com.johnsnowlabs.nlp:spark-nlp-silicon_2.12:5.3.2AArch64
spark-shell --packages com.johnsnowlabs.nlp:spark-nlp-aarch64_2.12:5.3.2
pyspark --packages com.johnsnowlabs.nlp:spark-nlp-aarch64_2.12:5.3.2Maven
spark-nlp on Apache Spark 3.0.x, 3.1.x, 3.2.x, 3.3.x, 3.4.x, and 3.5.x:
<dependency>
<groupId>com.johnsnowlabs.nlp</groupId>
<artifactId>spark-nlp_2.12</artifactId>
<version>5.3.2</version>
</dependency>spark-nlp-gpu:
<dependency>
<groupId>com.johnsnowlabs.nlp</groupId>
<artifactId>spark-nlp-gpu_2.12</artifactId>
<version>5.3.2</version>
</dependency>spark-nlp-silicon:
<dependency>
<groupId>com.johnsnowlabs.nlp</groupId>
<artifactId>spark-nlp-silicon_2.12</artifactId>
<version>5.3.2</version>
</dependency>spark-nlp-aarch64:
<dependency>
<groupId>com.johnsnowlabs.nlp</groupId>
<artifactId>spark-nlp-aarch64_2.12</artifactId>
<version>5.3.2</version>
</dependency>FAT JARs
-
CPU on Apache Spark 3.0.x/3.1.x/3.2.x/3.3.x/3.4.x/3.5.x: https://s3.amazonaws.com/auxdata.johnsnowlabs.com/public/jars/spark-nlp-assembly-5.3.2.jar
-
GPU on Apache Spark 3.0.x/3.1.x/3.2.x/3.3.x/3.4.x/3.5.x: https://s3.amazonaws.com/auxdata.johnsnowlabs.com/public/jars/spark-nlp-gpu-assembly-5.3.2.jar
-
M1 on Apache Spark 3.0.x/3.1.x/3.2.x/3.3.x/3.4.x/3.5.x: https://s3.amazonaws.com/auxdata.johnsnowlabs.com/public/jars/spark-nlp-silicon-assembly-5.3.2.jar
-
AArch64 on Apache Spark 3.0.x/3.1.x/3.2.x/3.3.x/3.4.x/3.5.x: https://s3.amazonaws.com/auxdata.johnsnowlabs.com/public/jars/spark-nlp-aarch64-assembly-5.3.2.jar
What's Changed
- Add Spark NLP 5.3 to models.json [skip test] by @pabla in #14208
- Sparknlp 1010 adding missing notebooks to onnx and tensor flow transformers by @ahmedlone127 in #14192
- Add MPNetEmbeddings to annotator by @maziyarpanahi in #14202
- Fix XLMRoBertaForXX : revert the change in tfFile naming by @maziyarpanahi in #14204
- SPARKNLP-1026: Fix documentation for sparknlp.start() by @DevinTDHa in #14206
- uploading example/demos by @AbdullahMubeenAnwar in #14175
- release/523-release-candidate by @maziyarpanahi in #14211
- Models hub by @maziyarpanahi in #14212
Full Changelog: 5.3.1...5.3.2
Spark NLP 5.3.1: Patch release
🐛 Bug Fixes
- Fix
M2M100not working on the second run (closing ONNX session by mistake) 75d398e - Fix ONNX models failing in clusters like Databricks 8877454
- Fix
ZeroShotNerClassificationissue withNerConverter#14186 - Adding Colab notebook for M2M100 #14191
📖 Documentation
- Import models from TF Hub & HuggingFace
- Spark NLP Notebooks
- Models Hub with new models
- Spark NLP Articles
- Spark NLP in Action
- Spark NLP Documentation
- Spark NLP Scala APIs
- Spark NLP Python APIs
❤️ Community support
- Slack For live discussion with the Spark NLP community and the team
- GitHub Bug reports, feature requests, and contributions
- Discussions Engage with other community members, share ideas, and show off how you use Spark NLP!
- Medium Spark NLP articles
- YouTube Spark NLP video tutorials
Installation
Python
#PyPI
pip install spark-nlp==5.3.1Spark Packages
spark-nlp on Apache Spark 3.0.x, 3.1.x, 3.2.x, 3.3.x, 3.4.x, and 3.5.x: (Scala 2.12):
spark-shell --packages com.johnsnowlabs.nlp:spark-nlp_2.12:5.3.1
pyspark --packages com.johnsnowlabs.nlp:spark-nlp_2.12:5.3.1GPU
spark-shell --packages com.johnsnowlabs.nlp:spark-nlp-gpu_2.12:5.3.1
pyspark --packages com.johnsnowlabs.nlp:spark-nlp-gpu_2.12:5.3.1Apple Silicon (M1 & M2)
spark-shell --packages com.johnsnowlabs.nlp:spark-nlp-silicon_2.12:5.3.1
pyspark --packages com.johnsnowlabs.nlp:spark-nlp-silicon_2.12:5.3.1AArch64
spark-shell --packages com.johnsnowlabs.nlp:spark-nlp-aarch64_2.12:5.3.1
pyspark --packages com.johnsnowlabs.nlp:spark-nlp-aarch64_2.12:5.3.1Maven
spark-nlp on Apache Spark 3.0.x, 3.1.x, 3.2.x, 3.3.x, 3.4.x, and 3.5.x:
<dependency>
<groupId>com.johnsnowlabs.nlp</groupId>
<artifactId>spark-nlp_2.12</artifactId>
<version>5.3.1</version>
</dependency>spark-nlp-gpu:
<dependency>
<groupId>com.johnsnowlabs.nlp</groupId>
<artifactId>spark-nlp-gpu_2.12</artifactId>
<version>5.3.1</version>
</dependency>spark-nlp-silicon:
<dependency>
<groupId>com.johnsnowlabs.nlp</groupId>
<artifactId>spark-nlp-silicon_2.12</artifactId>
<version>5.3.1</version>
</dependency>spark-nlp-aarch64:
<dependency>
<groupId>com.johnsnowlabs.nlp</groupId>
<artifactId>spark-nlp-aarch64_2.12</artifactId>
<version>5.3.1</version>
</dependency>FAT JARs
-
CPU on Apache Spark 3.0.x/3.1.x/3.2.x/3.3.x/3.4.x/3.5.x: https://s3.amazonaws.com/auxdata.johnsnowlabs.com/public/jars/spark-nlp-assembly-5.3.1.jar
-
GPU on Apache Spark 3.0.x/3.1.x/3.2.x/3.3.x/3.4.x/3.5.x: https://s3.amazonaws.com/auxdata.johnsnowlabs.com/public/jars/spark-nlp-gpu-assembly-5.3.1.jar
-
M1 on Apache Spark 3.0.x/3.1.x/3.2.x/3.3.x/3.4.x/3.5.x: https://s3.amazonaws.com/auxdata.johnsnowlabs.com/public/jars/spark-nlp-silicon-assembly-5.3.1.jar
-
AArch64 on Apache Spark 3.0.x/3.1.x/3.2.x/3.3.x/3.4.x/3.5.x: https://s3.amazonaws.com/auxdata.johnsnowlabs.com/public/jars/spark-nlp-aarch64-assembly-5.3.1.jar
What's Changed
- [SPARKNLP-994] Solves ZeroShotNerClassification Issue by @danilojsl in #14186
- adding colab notebook for M2M100 by @AbdullahMubeenAnwar in #14191
- Release/531 release candidate by @maziyarpanahi in #14190
Full Changelog: 5.3.0...5.3.1
Contributors
Assets 2
Spark NLP 5.3.0: Introducing Llama-2 for CasualLM, M2M100 for Multilingual Translation, MPNet & DeBERTa Enhancements, New Document Similarity Features, Expanded ONNX & In-Memory Support, Updated Runtimes, Essential Bug Fixes, and More!
🎉 Celebrating 91 Million Downloads on PyPI - A Spark NLP Milestone! 🚀

We're thrilled to announce the release of Spark NLP 5.3.0, a monumental update that brings cutting-edge advancements and enhancements to the forefront of Natural Language Processing (NLP). This release underscores our commitment to providing the NLP community with state-of-the-art tools and models, furthering our mission to democratize NLP technologies.
This release also addresses critical bug fixes, enhancing the stability and reliability of Spark NLP. Fixes include Spark NLP configuration adjustments, score calculation corrections, input validation, notebook improvements, and serialization issues.
We invite the community to explore these new features and enhancements, and we look forward to seeing the innovative applications that Spark NLP 5.3.0 will enable. 🌟
🔥 New Features & Enhancements
- Llama-2 Integration: We're introducing Llama-2 along with models fine-tuned on this architecture, marking our first foray into CasualLM annotators in ONNX. This groundbreaking addition supports quantization in INT4 and INT8 for CPUs, optimizing performance and efficiency.

In this work, we develop and release Llama 2, a collection of pretrained and fine-tuned large language models (LLMs) ranging in scale from 7 billion to 70 billion parameters. Our fine-tuned LLMs, called Llama 2-Chat, are optimized for dialogue use cases. Our models outperform open-source chat models on most benchmarks we tested, and based on our human evaluations for helpfulness and safety, may be a suitable substitute for closed-source models. We provide a detailed description of our approach to fine-tuning and safety improvements of Llama 2-Chat in order to enable the community to build on our work and contribute to the responsible development of LLMs. - https://ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models/
We have made LLAMA2Transformer annotator compatible with ONNX exports and quantizations:
- 16 bit (CUDA only)
- 8 bit (CPU or CUDA)
- 4 bit (CPU or CIDA)
As always, we made this feature super easy and scalable:
doc_assembler = DocumentAssembler() \
.setInputCol("text") \
.setOutputCol("documents")
llama2 = LLAMA2Transformer \
.pretrained() \
.setMaxOutputLength(50) \
.setDoSample(False) \
.setInputCols(["documents"]) \
.setOutputCol("generation")We will continue improving this annotator and import more models in the future
- Multilingual Translation with M2M100: The
M2M100model sets a new benchmark for multilingual translation, supporting direct translation across 9,900 language pairs from 100 languages. This feature represents a significant leap in breaking down language barriers in global communication.

Existing work in translation demonstrated the potential of massively multilingual machine translation by training a single model able to translate between any pair of languages. However, much of this work is English-Centric by training only on data which was translated from or to English. While this is supported by large sources of training data, it does not reflect translation needs worldwide. In this work, we create a true Many-to-Many multilingual translation model that can translate directly between any pair of 100 languages. We build and open source a training dataset that covers thousands of language directions with supervised data, created through large-scale mining. Then, we explore how to effectively increase model capacity through a combination of dense scaling and language-specific sparse parameters to create high quality models. Our focus on non-English-Centric models brings gains of more than 10 BLEU when directly translating between non-English directions while performing competitively to the best single systems of WMT. We open-source our scripts so that others may reproduce the data, evaluation, and final M2M-100 model. - https://arxiv.org/pdf/2010.11125.pdf
m2m100 = M2M100Transformer.pretrained() \
.setInputCols(["documents"]) \
.setMaxOutputLength(50) \
.setOutputCol("generation") \
.setSrcLang("zh") \
.setTgtLang("en")
- Document Similarity and Retrieval: We've implemented a retrieval feature in our
DocumentSimilarityannotator, offering an efficient and scalable solution for ranking documents based on similarity, ideal for retrieval-augmented generation (RAG) applications.
query = "Florence in Italy, is among the most beautiful cities in Europe."
doc_similarity_ranker = DocumentSimilarityRankerApproach()\
.setInputCols("sentence_embeddings")\
.setOutputCol("doc_similarity_rankings")\
.setSimilarityMethod("brp")\ # brp for BucketedRandomProjectionLSH and mh for MinHashLSH
.setNumberOfNeighbours(3)\
.setVisibleDistances(True)\
.setIdentityRanking(True)\
.asRetriever(query)- NEW: Introducing
MPNetForSequenceClassificationannotator for sequence classification tasks. This annotator is based on the MPNet architecture, enhances our capabilities in sequence classification tasks, offering more precise and context-aware processing. - NEW: Introducing
MPNetForQuestionAnsweringannotator for question answering tasks. This annotator is based on the MPNet architecture, enhances our capabilities in question answering tasks, offering more precise and context-aware processing. - NEW: Introducing a new
DeBertaForZeroShotClassificationannotator, leveraging the DeBERTa architecture, introduces sophisticated zero-shot classification capabilities, enabling the classification of text into predefined classes without direct example training. - NEW: Add support for in-memory use of
WordEmbeddingsModelannotator in serverless clusters. We initially introduced the in-memory feature for this annotator for users inside Kubernetes clusters without anyHDFS. However, today it runs without any issuelocally, on GoogleColab,Kaggle,Databricks,AWS EMR,GCP, andAWS Glue. - Add ONNX support for
BertForZeroShotClassificationannotator - Introduce new Whisper Large and Distil models.
- Support new Databricks Runtimes of
14.2,14.3,14.2 ML,14.3 ML,14.2 GPU, and14.3 GPU. - Support new EMR versions
6.15.0and7.0.0. - Add a notebook to fine-tune a BERT for Sentence Embeddings in Hugging Face and import it into Spark NLP.
- Add a notebook to import BERT for Zero-Shot classification from Hugging Face.
- Add a notebook to import DeBERTa for Zero-Shot classification from Hugging Face.
- Update
EntityRulerdocumentation. - Improve SBT project and resolve warnings (almost!).
- Update ONNX Runtime to 1.17.0 to enjoy the following features in upcoming releases:
- Support for CUDA 12.1
- Enhanced security for Linux binaries to comply with BinSkim, added Windows ARM64X source build support, removed Windows ARM32 binaries, and introduced AMD GPU packages.
- Optimized graph inlining, added custom logger support at the session level, and introduced new logging and tracing features for session and execution provider options.
- Added 4bit quantization support for NVIDIA GPU and ARM64.
🐛 Bug Fixes
- Fix Spark NLP Configuration to set
cluster_tmp_diron Databricks' DBFS viaspark.jsl.settings.storage.cluster_tmp_dir#14129 - Fix score calculation in
RoBertaForQuestionAnsweringannotator #14147 - Fix optional input col validations #14153
- Fix notebooks for importing DeBERTa classifiers #14154
- Fix GPT2 deserialization over the cluster (Databricks) #14177
ℹ️ Known Issues
- Llama-2, M2M100, and Whisper Large do not work in a cluster. We are working on how best share these large models over a cluster and will provide a fix in the future releases
- Previously some ONNX models did not work on CUDA 12.x as we have reported this problem - We have not tested this yet, but it should be resolved in onnxruntime 1.17.0 in Spark NLP 5.3.0
💾 Models
The complete list of all 37000+ models & pipelines in 230+ languages is available on Models Hub
📓 New Notebooks
- You can visit Import Transformers in Spark NLP
- You can visit Spark NLP Examples for 100+ examples
📖 Documentation
- Import models from TF Hub & HuggingFace
- Spark NLP Notebooks
- Models Hub with new models
- Spark NLP Articles
- Spark NLP in Action
- Spark NLP Documentation
- Spark NLP Scala APIs
- [Spark NLP Pyt...
Spark NLP 5.2.3: ONNX support for XLM-RoBERTa Token and Sequence Classifications, and Question Answering task, AWS SDK optimizations, New notebooks, Over 400 new state-of-the-art Transformer Models in ONNX, and bug fixes!
📢 Overview
Spark NLP 5.2.3 🚀 comes with an array of exciting features and optimizations. We're thrilled to announce support for ONNX Runtime in XLMRoBertaForTokenClassification, XLMRoBertaForSequenceClassification, and XLMRoBertaForQuestionAnswering annotators. This release also showcases a significant refinement in the use of AWS SDK in Spark NLP, shifting from aws-java-sdk-bundle to aws-java-sdk-s3, resulting in a substantial ~320MB reduction in library size and a 20% increase in startup speed, new notebooks to import external models from Hugging Face, over 400+ new LLM models, and more!
We're pleased to announce that our Models Hub now boasts 36,000+ free and truly open-source models & pipelines 🎉. Our deepest gratitude goes out to our community for their invaluable feedback, feature suggestions, and contributions.
🔥 New Features & Enhancements
- NEW: Introducing support for ONNX Runtime in
XLMRoBertaForTokenClassificationannotator - NEW: Introducing support for ONNX Runtime in
XLMRoBertaForSequenceClassificationannotator - NEW: Introducing support for ONNX Runtime in
XLMRoBertaForQuestionAnsweringannotator - Refactored the use of AWS SDK in Spark NLP, transitioning from the
aws-java-sdk-bundleto theaws-java-sdk-s3dependency. This change has resulted in a 318MB reduction in the library's overall size and has enhanced the Spark NLP startup time by 20%. For instance, usingsparknlp.start()in Google Colab is now 14 to 20 seconds faster. Special thanks to @c3-avidmych for requesting this feature. - Add new notebooks to import
DeBertaForQuestionAnswering,DebertaForSequenceClassification, andDeBertaForTokenClassificationmodels from HuggingFace - Add a new
DocumentTokenSplitternotebook - Add a new training NER notebook by using DeBerta Embeddings
- Add a new training text classification notebook by using
INSTRUCTOREmbeddings - Update
RoBertaForTokenClassificationnotebook - Update
RoBertaForSequenceClassificationnotebook - Update
OpenAICompletionnotebook with newgpt-3.5-turbo-instructmodel
🐛 Bug Fixes
- Fix
BGEEmbeddingsnot downloading in Python
ℹ️ Known Issues
- ONNX models crash when they are used in Colab's
T4 GPUruntime #14109
📓 New Notebooks
📖 Documentation
- Import models from TF Hub & HuggingFace
- Spark NLP Notebooks
- Models Hub with new models
- Spark NLP Articles
- Spark NLP in Action
- Spark NLP Documentation
- Spark NLP Scala APIs
- Spark NLP Python APIs
❤️ Community support
- Slack For live discussion with the Spark NLP community and the team
- GitHub Bug reports, feature requests, and contributions
- Discussions Engage with other community members, share ideas, and show off how you use Spark NLP!
- Medium Spark NLP articles
- YouTube Spark NLP video tutorials
Installation
Python
#PyPI
pip install spark-nlp==5.2.3Spark Packages
spark-nlp on Apache Spark 3.0.x, 3.1.x, 3.2.x, 3.3.x, 3.4.x, and 3.5.x: (Scala 2.12):
spark-shell --packages com.johnsnowlabs.nlp:spark-nlp_2.12:5.2.3
pyspark --packages com.johnsnowlabs.nlp:spark-nlp_2.12:5.2.3GPU
spark-shell --packages com.johnsnowlabs.nlp:spark-nlp-gpu_2.12:5.2.3
pyspark --packages com.johnsnowlabs.nlp:spark-nlp-gpu_2.12:5.2.3Apple Silicon (M1 & M2)
spark-shell --packages com.johnsnowlabs.nlp:spark-nlp-silicon_2.12:5.2.3
pyspark --packages com.johnsnowlabs.nlp:spark-nlp-silicon_2.12:5.2.3AArch64
spark-shell --packages com.johnsnowlabs.nlp:spark-nlp-aarch64_2.12:5.2.3
pyspark --packages com.johnsnowlabs.nlp:spark-nlp-aarch64_2.12:5.2.3Maven
spark-nlp on Apache Spark 3.0.x, 3.1.x, 3.2.x, 3.3.x, 3.4.x, and 3.5.x:
<dependency>
<groupId>com.johnsnowlabs.nlp</groupId>
<artifactId>spark-nlp_2.12</artifactId>
<version>5.2.3</version>
</dependency>spark-nlp-gpu:
<dependency>
<groupId>com.johnsnowlabs.nlp</groupId>
<artifactId>spark-nlp-gpu_2.12</artifactId>
<version>5.2.3</version>
</dependency>spark-nlp-silicon:
<dependency>
<groupId>com.johnsnowlabs.nlp</groupId>
<artifactId>spark-nlp-silicon_2.12</artifactId>
<version>5.2.3</version>
</dependency>spark-nlp-aarch64:
<dependency>
<groupId>com.johnsnowlabs.nlp</groupId>
<artifactId>spark-nlp-aarch64_2.12</artifactId>
<version>5.2.3</version>
</dependency>FAT JARs
-
CPU on Apache Spark 3.0.x/3.1.x/3.2.x/3.3.x/3.4.x/3.5.x: https://s3.amazonaws.com/auxdata.johnsnowlabs.com/public/jars/spark-nlp-assembly-5.2.3.jar
-
GPU on Apache Spark 3.0.x/3.1.x/3.2.x/3.3.x/3.4.x/3.5.x: https://s3.amazonaws.com/auxdata.johnsnowlabs.com/public/jars/spark-nlp-gpu-assembly-5.2.3.jar
-
M1 on Apache Spark 3.0.x/3.1.x/3.2.x/3.3.x/3.4.x/3.5.x: https://s3.amazonaws.com/auxdata.johnsnowlabs.com/public/jars/spark-nlp-silicon-assembly-5.2.3.jar
-
AArch64 on Apache Spark 3.0.x/3.1.x/3.2.x/3.3.x/3.4.x/3.5.x: https://s3.amazonaws.com/auxdata.johnsnowlabs.com/public/jars/spark-nlp-aarch64-assembly-5.2.3.jar
What's Changed
- HuggingFace_ONNX_in_Spark_NLP_RoBertaForSequenceClassification updated by @AbdullahMubeenAnwar in #14122
- HuggingFace_ONNX_in_Spark_NLP_RoBertaForTokenClassification updated by @AbdullahMubeenAnwar in #14123
- adding notebooks for onnx Deberta Import from Huggingface by @ahmedlone127 in #14126
- Sparknlp 967 add onnx support to xlm roberta classifiers by @ahmedlone127 in #14130
- adding BGEEmbeddings to resource downloader by @ahmedlone127 in #14133
- adding missing notebooks by @ahmedlone127 in #14135
- Uploading and fixing example notebooks to spark-nlp by @AbdullahMubeenAnwar in #14137
- [SPARKNLP-978] Refactoring to use aws-java-sdk-s3 library by @danilojsl in #14136
- Models hub by @maziyarpanahi in #14141
- Release/523 release candidate by @maziyarpanahi in #14140
New Contributors
- @AbdullahMubeenAnwar made their first contribution in #14122
Full Changelog: https://github.com/JohnSnowLabs/spark-nlp/compare/5.2...
Contributors
Assets 2
Spark NLP 5.2.2: Patch release
Spark NLP 5.2.2 🚀 is a patch release with a bug fixe, improvements, and more than 2000 new state-of-the-art LLM models.
We're pleased to announce that our Models Hub now boasts 36,000+ free and truly open-source models & pipelines 🎉. Our deepest gratitude goes out to our community for their invaluable feedback, feature suggestions, and contributions.
🔥 Enhancements
- Update
aws-java-sdk-bundledependency to1.12.500version that represents no CVEs - Add a new BGE notebook to import models into Spark NLP
- Upload the new true
BGEmodels (small,base, andlarge) to Spark NLP for text embeddings
🐛 Bug Fixes
- Fix the missing
BGEEmbeddingsfrom annotator module in Python
ℹ️ Known Issues
- ONNX models crash when they are used in Colab's
T4 GPUruntime #14109
📓 New Notebooks
| Notebooks |
|---|
| Import BGE models in TensorFlow from HuggingFace 🤗 into Spark NLP 🚀 |
📖 Documentation
- Import models from TF Hub & HuggingFace
- Spark NLP Notebooks
- Models Hub with new models
- Spark NLP Articles
- Spark NLP in Action
- Spark NLP Documentation
- Spark NLP Scala APIs
- Spark NLP Python APIs
❤️ Community support
- Slack For live discussion with the Spark NLP community and the team
- GitHub Bug reports, feature requests, and contributions
- Discussions Engage with other community members, share ideas, and show off how you use Spark NLP!
- Medium Spark NLP articles
- YouTube Spark NLP video tutorials
Installation
Python
#PyPI
pip install spark-nlp==5.2.2Spark Packages
spark-nlp on Apache Spark 3.0.x, 3.1.x, 3.2.x, 3.3.x, 3.4.x, and 3.5.x: (Scala 2.12):
spark-shell --packages com.johnsnowlabs.nlp:spark-nlp_2.12:5.2.2
pyspark --packages com.johnsnowlabs.nlp:spark-nlp_2.12:5.2.2GPU
spark-shell --packages com.johnsnowlabs.nlp:spark-nlp-gpu_2.12:5.2.2
pyspark --packages com.johnsnowlabs.nlp:spark-nlp-gpu_2.12:5.2.2Apple Silicon (M1 & M2)
spark-shell --packages com.johnsnowlabs.nlp:spark-nlp-silicon_2.12:5.2.2
pyspark --packages com.johnsnowlabs.nlp:spark-nlp-silicon_2.12:5.2.2AArch64
spark-shell --packages com.johnsnowlabs.nlp:spark-nlp-aarch64_2.12:5.2.2
pyspark --packages com.johnsnowlabs.nlp:spark-nlp-aarch64_2.12:5.2.2Maven
spark-nlp on Apache Spark 3.0.x, 3.1.x, 3.2.x, 3.3.x, 3.4.x, and 3.5.x:
<dependency>
<groupId>com.johnsnowlabs.nlp</groupId>
<artifactId>spark-nlp_2.12</artifactId>
<version>5.2.2</version>
</dependency>spark-nlp-gpu:
<dependency>
<groupId>com.johnsnowlabs.nlp</groupId>
<artifactId>spark-nlp-gpu_2.12</artifactId>
<version>5.2.2</version>
</dependency>spark-nlp-silicon:
<dependency>
<groupId>com.johnsnowlabs.nlp</groupId>
<artifactId>spark-nlp-silicon_2.12</artifactId>
<version>5.2.2</version>
</dependency>spark-nlp-aarch64:
<dependency>
<groupId>com.johnsnowlabs.nlp</groupId>
<artifactId>spark-nlp-aarch64_2.12</artifactId>
<version>5.2.2</version>
</dependency>FAT JARs
-
CPU on Apache Spark 3.0.x/3.1.x/3.2.x/3.3.x/3.4.x/3.5.x: https://s3.amazonaws.com/auxdata.johnsnowlabs.com/public/jars/spark-nlp-assembly-5.2.2.jar
-
GPU on Apache Spark 3.0.x/3.1.x/3.2.x/3.3.x/3.4.x/3.5.x: https://s3.amazonaws.com/auxdata.johnsnowlabs.com/public/jars/spark-nlp-gpu-assembly-5.2.2.jar
-
M1 on Apache Spark 3.0.x/3.1.x/3.2.x/3.3.x/3.4.x/3.5.x: https://s3.amazonaws.com/auxdata.johnsnowlabs.com/public/jars/spark-nlp-silicon-assembly-5.2.2.jar
-
AArch64 on Apache Spark 3.0.x/3.1.x/3.2.x/3.3.x/3.4.x/3.5.x: https://s3.amazonaws.com/auxdata.johnsnowlabs.com/public/jars/spark-nlp-aarch64-assembly-5.2.2.jar
What's Changed
- Models hub by @maziyarpanahi in #14118
- Release/522 release candidate by @maziyarpanahi in #14117
Full Changelog: 5.2.1...5.2.2
Spark NLP 5.2.1: Official support for Apache Spark 3.5, Introducing BGE annotator for Text Embeddings, ONNX support for DeBERTa Token and Sequence Classifications, and Question Answering task, new Databricks 14.x runtimes, Over 400 new state-of-the-art Transformer Models in ONNX, and bug fixes!
📢 Overview
Spark NLP 5.2.1 🚀 comes with full compatibility with Spark/PySpark 3.5, brand new BGEEmbeddings to load BGE models for text embeddings, new ONNX support for DeBertaForTokenClassification, DeBertaForSequenceClassification, and DeBertaForQuestionAnswering annotators. Additionally, we've added over 400 state-of-the-art transformer models in ONNX format to ensure rapid inference for multi-class/multi-label classification models.
We're pleased to announce that our Models Hub now boasts 30,000+ free and truly open-source models & pipelines 🎉. Our deepest gratitude goes out to our community for their invaluable feedback, feature suggestions, and contributions.
🔥 New Features & Enhancements
- NEW: Introducing
full supportfor Apache Spark and PySpark 3.5 that comes with lots of improvements for Spark Connect: https://spark.apache.org/releases/spark-release-3-5-0.html#highlights - NEW: Welcoming 6 new Databricks runtimes officially with support for new Spark 3.5:
- Databricks 14.0
- Databricks 14.0 ML
- Databricks 14.0 ML GPU
- Databricks 14.1
- Databricks 14.1 ML
- Databricks 14.1 ML GPU
- Databricks 14.2
- Databricks 14.2 ML
- Databricks 14.2 ML GPU
- NEW: Introducing the
BGEEmbeddingsannotator for Spark NLP. This annotator enables the integration ofBGEmodels, based on the BERT architecture, into Spark NLP. TheBGEEmbeddingsannotator is designed for generating dense vectors suitable for a variety of applications, includingretrieval,classification,clustering, andsemantic search. Additionally, it is compatible withvector databasesused inLarge Language Models (LLMs). - NEW: Introducing support for ONNX Runtime in
DeBertaForTokenClassificationannotator - NEW: Introducing support for ONNX Runtime in
DeBertaForSequenceClassificationannotator - NEW: Introducing support for ONNX Runtime in
DeBertaForQuestionAnsweringannotator - Add a new notebook to show how to import any model from
T5family into Spark NLP with TensorFlow format - Add a new notebook to show how to import any model from
T5family into Spark NLP with ONNX format - Add a new notebook to show how to import any model from
MarianNMTfamily into Spark NLP with ONNX format
🐛 Bug Fixes
- Fix serialization issue in
DocumentTokenSplitterannotator failing to be saved and loaded in a Pipeline - Fix serialization issue in
DocumentCharacterTextSplitterannotator failing to be saved and loaded in a Pipeline
ℹ️ Known Issues
- ONNX models crash when they are used in Colab's
T4 GPUruntime #14109
📓 New Notebooks
📖 Documentation
- Import models from TF Hub & HuggingFace
- Spark NLP Notebooks
- Models Hub with new models
- Spark NLP Articles
- Spark NLP in Action
- Spark NLP Documentation
- Spark NLP Scala APIs
- Spark NLP Python APIs
❤️ Community support
- Slack For live discussion with the Spark NLP community and the team
- GitHub Bug reports, feature requests, and contributions
- Discussions Engage with other community members, share ideas, and show off how you use Spark NLP!
- Medium Spark NLP articles
- YouTube Spark NLP video tutorials
Installation
Python
#PyPI
pip install spark-nlp==5.2.1Spark Packages
spark-nlp on Apache Spark 3.0.x, 3.1.x, 3.2.x, 3.3.x, 3.4.x, and 3.5.x: (Scala 2.12):
spark-shell --packages com.johnsnowlabs.nlp:spark-nlp_2.12:5.2.1
pyspark --packages com.johnsnowlabs.nlp:spark-nlp_2.12:5.2.1GPU
spark-shell --packages com.johnsnowlabs.nlp:spark-nlp-gpu_2.12:5.2.1
pyspark --packages com.johnsnowlabs.nlp:spark-nlp-gpu_2.12:5.2.1Apple Silicon (M1 & M2)
spark-shell --packages com.johnsnowlabs.nlp:spark-nlp-silicon_2.12:5.2.1
pyspark --packages com.johnsnowlabs.nlp:spark-nlp-silicon_2.12:5.2.1AArch64
spark-shell --packages com.johnsnowlabs.nlp:spark-nlp-aarch64_2.12:5.2.1
pyspark --packages com.johnsnowlabs.nlp:spark-nlp-aarch64_2.12:5.2.1Maven
spark-nlp on Apache Spark 3.0.x, 3.1.x, 3.2.x, 3.3.x, 3.4.x, and 3.5.x:
<dependency>
<groupId>com.johnsnowlabs.nlp</groupId>
<artifactId>spark-nlp_2.12</artifactId>
<version>5.2.1</version>
</dependency>spark-nlp-gpu:
<dependency>
<groupId>com.johnsnowlabs.nlp</groupId>
<artifactId>spark-nlp-gpu_2.12</artifactId>
<version>5.2.1</version>
</dependency>spark-nlp-silicon:
<dependency>
<groupId>com.johnsnowlabs.nlp</groupId>
<artifactId>spark-nlp-silicon_2.12</artifactId>
<version>5.2.1</version>
</dependency>spark-nlp-aarch64:
<dependency>
<groupId>com.johnsnowlabs.nlp</groupId>
<artifactId>spark-nlp-aarch64_2.12</artifactId>
<version>5.2.1</version>
</dependency>FAT JARs
-
CPU on Apache Spark 3.0.x/3.1.x/3.2.x/3.3.x/3.4.x/3.5.x: https://s3.amazonaws.com/auxdata.johnsnowlabs.com/public/jars/spark-nlp-assembly-5.2.1.jar
-
GPU on Apache Spark 3.0.x/3.1.x/3.2.x/3.3.x/3.4.x/3.5.x: https://s3.amazonaws.com/auxdata.johnsnowlabs.com/public/jars/spark-nlp-gpu-assembly-5.2.1.jar
-
M1 on Apache Spark 3.0.x/3.1.x/3.2.x/3.3.x/3.4.x/3.5.x: https://s3.amazonaws.com/auxdata.johnsnowlabs.com/public/jars/spark-nlp-silicon-assembly-5.2.1.jar
-
AArch64 on Apache Spark 3.0.x/3.1.x/3.2.x/3.3.x/3.4.x/3.5.x: https://s3.amazonaws.com/auxdata.johnsnowlabs.com/public/jars/spark-nlp-aarch64-assembly-5.2.1.jar
What's Changed
- SPARKNLP-955: DocumentCharacterTextSplitter Bug Fix by @DevinTDHa in #14088
- SPARKNLP-951 & SPARKNLP-952: Added example notebooks for Marian and T5 by @DevinTDHa in #14089
- Added BGE Embeddings by @dcecchini in #14090
- adding onnx support to DeberatForXXX annotators by @ahmedlone127 in #14096
- [SPARKNLP-957] Solves average pooling computation by @danilojsl in #14104
- [SPARKNLP-949] Adding changes for spark 3.5 compatibility by @danilojsl in #14105
- [SPARKNLP-961] Adding ONNX configs to README by @danilojsl in #14111
- Models hub by @maziyarpanahi in #14113
- Release/521 release candidate by @maziyarpanahi in #14112
Full Changelog: 5.2.0...5.2.1
Spark NLP 5.2.0: Introducing a Zero-Shot Image Classification by CLIP, ONNX support for T5, Marian, and CamemBERT, a new Text Splitter annotator, Over 8000 state-of-the-art Transformer Models in ONNX, bug fixes, and more!
🎉 Celebrating 80 Million Downloads on PyPI - A Spark NLP Milestone! 🚀

We are thrilled to announce that Spark NLP has reached a remarkable milestone of 80 million downloads on PyPI! This achievement is a testament to the strength and dedication of our community.
A heartfelt thank you to each and every one of you who has contributed, used, and supported Spark NLP. Your invaluable feedback, contributions, and enthusiasm have played a crucial role in evolving Spark NLP into an award-winning, production-ready, and scalable open-source NLP library.
As we celebrate this milestone, we're also excited to announce the release of Spark NLP 5.2.0! This new version marks another step forward in our journey, new features, improved performance, bug fixes, and extending our Models Hub to 30,000 open-source and forever free models with 8000 new state-of-the-art language models in 5.2.0 release.
Here's to many more milestones, breakthroughs, and advancements! 🌟
🔥 New Features & Enhancements
- NEW: Introducing the
CLIPForZeroShotClassificationfor Zero-Shot Image Classification using OpenAI's CLIP models. CLIP is a state-of-the-art computer vision designed to recognize a specific, pre-defined group of object categories. CLIP is a multi-modal vision and language model. It can be used for Zero-Shot image classification. To achieve this, CLIP utilizes a Vision Transformer (ViT) to extract visual attributes and a causal language model to process text features. These features from both text and images are then mapped to a common latent space having the same dimensions. The similarity score is calculated using the dot product of the projected image and text features in this space.

CLIP (Contrastive Language–Image Pre-training) builds on a large body of work on zero-shot transfer, natural language supervision, and multimodal learning. The idea of zero-data learning dates back over a decade but until recently was mostly studied in computer vision as a way of generalizing to unseen object categories. A critical insight was to leverage natural language as a flexible prediction space to enable generalization and transfer. In 2013, Richer Socher and co-authors at Stanford developed a proof of concept by training a model on CIFAR-10 to make predictions in a word vector embedding space and showed this model could predict two unseen classes. The same year DeVISE scaled this approach and demonstrated that it was possible to fine-tune an ImageNet model so that it could generalize to correctly predicting objects outside the original 1000 training set. - CLIP: Connecting text and images
As always, we made this feature super easy and scalable:
image_assembler = ImageAssembler() \
.setInputCol("image") \
.setOutputCol("image_assembler")
labels = [
"a photo of a bird",
"a photo of a cat",
"a photo of a dog",
"a photo of a hen",
"a photo of a hippo",
"a photo of a room",
"a photo of a tractor",
"a photo of an ostrich",
"a photo of an ox",
]
image_captioning = CLIPForZeroShotClassification \
.pretrained() \
.setInputCols(["image_assembler"]) \
.setOutputCol("label") \
.setCandidateLabels(labels)- NEW: Introducing the
DocumentTokenSplitterwhich allows users to split large documents into smaller chunks to be used in RAG with LLM models - NEW: Introducing support for ONNX Runtime in T5Transformer annotator
- NEW: Introducing support for ONNX Runtime in MarianTransformer annotator
- NEW: Introducing support for ONNX Runtime in BertSentenceEmbeddings annotator
- NEW: Introducing support for ONNX Runtime in XlmRoBertaSentenceEmbeddings annotator
- NEW: Introducing support for ONNX Runtime in CamemBertForQuestionAnswering, CamemBertForTokenClassification, and CamemBertForSequenceClassification annotators
- Adding a caching support for newly imported T5 models in TF format to improve the performance to be competitive to ONNX version
- Refactor ZIP utility and add new tests for both ZipArchiveUtil and OnnxWrapper thanks to @anqini
- Refactor ONNX and add OnnxSession to broadcast to improve stability in some cluster setups
- Update ONNX Runtime to 1.16.3 to enjoy the following features in upcoming releases:
- Support for serialization of models >=2GB
- Support for fp16 and bf16 tensors as inputs and outputs
- Improve LLM quantization accuracy with smoothquant
- Support 4-bit quantization on CPU
- Optimize BeamScore to improve BeamSearch performance
- Add FlashAttention v2 support for Attention, MultiHeadAttention and PackedMultiHeadAttention ops
🐛 Bug Fixes
- Fix random dimension mismatch in E5Embeddings and MPNetEmbeddings due to a missing average_pool after last_hidden_state in the output
- Fix batching exception in E5 and MPNet embeddings annotators failing when sentence is used instead of document
- Fix chunk construction when an entity is found
- Fix a bug in library's version in Scala where it was pointing to 5.1.2 wrongly
- Fix Whisper models not downloading due to wrong library's version
- Fix and refactor saving best model based on given metrics during NerDL training
ℹ️ Known Issues
- Some annotators are not yet compatible with Apache Spark and PySpark 3.5.x release. Due to this, we have changed the support matrix for Spark/PySpark 3.5.x to
Partiallyuntil we are 100% compatible.
💾 Models
Spark NLP 5.2.0 comes with more than 8000+ new state-of-the-art pretrained transformer models in multi-languages.
The complete list of all 30000+ models & pipelines in 230+ languages is available on Models Hub
📓 New Notebooks
- You can visit Import Transformers in Spark NLP
- You can visit Spark NLP Examples for 100+ examples
📖 Documentation
- Import models from TF Hub & HuggingFace
- Spark NLP Notebooks
- Models Hub with new models
- Spark NLP Articles
- Spark NLP in Action
- Spark NLP Documentation
- Spark NLP Scala APIs
- Spark NLP Python APIs
❤️ Community support
- Slack For live discussion with the Spark NLP community and the team
- GitHub Bug reports, feature requests, and contributions
- Discussions Engage with other community members, share ideas,
and show off how you use Spark NLP! - Medium Spark NLP articles
- JohnSnowLabs official Medium
- YouTube Spark NLP video tutorials
Installation
Python
#PyPI
pip install spark-nlp==5.2.0Spark Packages
spark-nlp on Apache Spark 3.0.x, 3.1.x, 3.2.x, 3.3.x, and 3.4.x (Scala 2.12):
spark-shell --packages com.johnsnowlabs.nlp:spark-nlp_2.12:5.2.0
pyspark --packages com.johnsnowlabs.nlp:spark-nlp_2.12:5.2.0GPU
spark-shell --packages com.johnsnowlabs.nlp:spark-nlp-gpu_2.12:5.2.0
pyspark --packages com.johnsnowlabs.nlp:spark-nlp-gpu_2.12:5.2.0Apple Silicon (M1 & M2)
spark-shell --packages com.johnsnowlabs.nlp:spark-nlp-silicon_2.12...