The current era is defined by rapid technological advancements that made innovation a central focus for both academic and industrial sectors. Understanding how new technologies are adopted by individuals, firms, and societies is crucial for strategic planning and development.
With the vast amount of data and computational power available today, there is an opportunity to improve our understanding of technology adoption using AI methods. AI techniques, such as natural language processing (NLP) and machine learning, can streamline complex patent-related tasks like classification and retrieval. This study is carried out to utilize AI methodologies, specifically text embeddings and patent clustering, to analyze patent data and model the technology life cycle and adoption process. By incorporating these findings into S-curve models, we expect to provide a detailed view of technological trends which will benefit industry analysts and researchers.
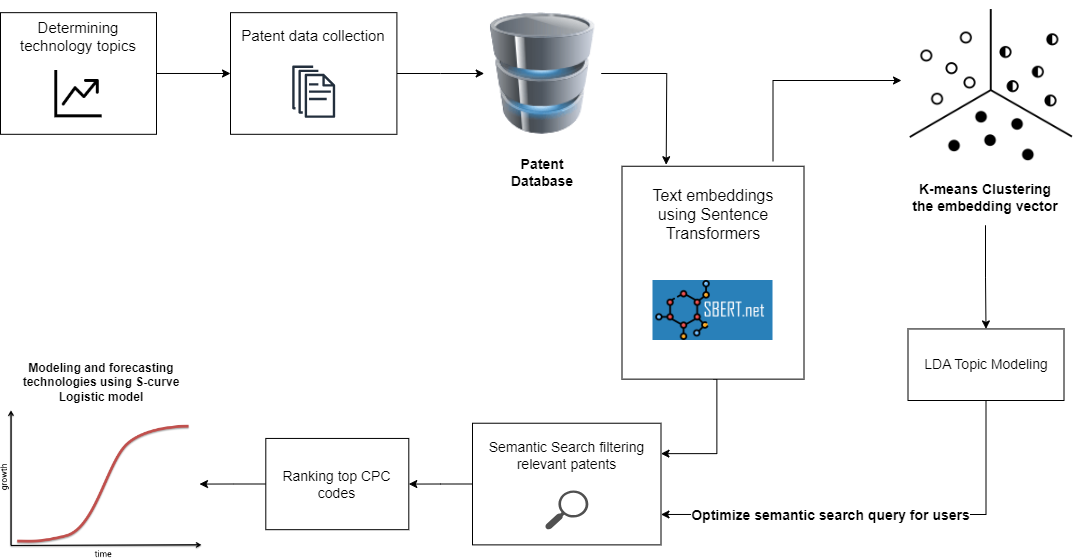
The suggested methodology is represented with a process flow covering main steps:
- Data collection
- Database integration
- Data preprocessing
- Text embeddings using pre-trained sentence transformers
- Patent clustering and topic modelling
- Filtering relevant patent using semantic search algorithm
- Modeling and forecasting the S-curves to analyze the technology adoption growth model.
| Patent Database | Link |
|---|---|
| Advanced Search USPTO | |
| Patsnap |
forecasting-tech-adoption/
├── data/ # collected patent sources
│ ├── raw/
│ └── processed/
├── img/ # Images
├── models/ # Models for each source and data pipeline
├── notebooks/ # notebooks storing scrpits for processing and analysis
├── src/ # common scripts
├── docs/ # Project documentation
├── .gitattributes
├── .gitignore
└── README.md
The methodology involves selecting target technologies, obtaining relevant patent data from databases such as USPTO and Patsnap, and processing obtained data using text embeddings, clustering, and topic modeling. This refined data is used for semantic searches, filtering relevant patents, and predicting future trends using logistic growth models. The methodology's application to technologies like 'Unmanned Aerial Vehicle' and 'Security Data Processing' demonstrates its efficiency in extracting trends and related CPC codes. These overall process offers a clear understanding of the selected technologies' development stages.
| Dataset | S-curves | Embedding Vectors | Clusters |
|---|---|---|---|
| USPTO |     |
 |
 |
| Patsnap |     |
 |
 |
- Broadening the Methodology: Can be applied to a wider range of topics across multiple technology areas.
- Global Perspective: More comprehensive analysis can be done by taking data from additional sources such as European Patent Office (EPO), Japan Patent Office (JPO), TÜRKPATENT, etc.
- Dynamic Prediction Models: Models that can be updated in real time can be developed.
- User Friendly Application: An application that allows users to enter queries and create dynamic models can be developed.