Batch Renormalization algorithm implementation in Keras 2.0+. Original paper by Sergey Ioffe, Batch Renormalization: Towards Reducing Minibatch Dependence in Batch-Normalized Models.
This implementation of BatchRenormalization is inconsistent with the original paper and therefore results may not be similar !
For discussion on the inconsistency of this implementation, refer here : keras-team/keras-contrib#17
Add the batch_renorm.py script into your repository, and import the BatchRenormalization layer.
Eg. You can replace Keras BatchNormalization layers with BatchRenormalization layers.
from batch_renorm import BatchRenormalization
Using BatchRenormalization layers requires slightly more time than the simpler BatchNormalization layer.
Observed speed differences in WRN-16-4 with respect to BatchNormalization on a 980M GPU:
-
Batch Normalization : 137 seconds per epoch.
-
Batch Renormalization (Mode 0) : 152 seconds per epoch.
-
Batch Renormalization (Mode 2) : 142 seconds per epoch.
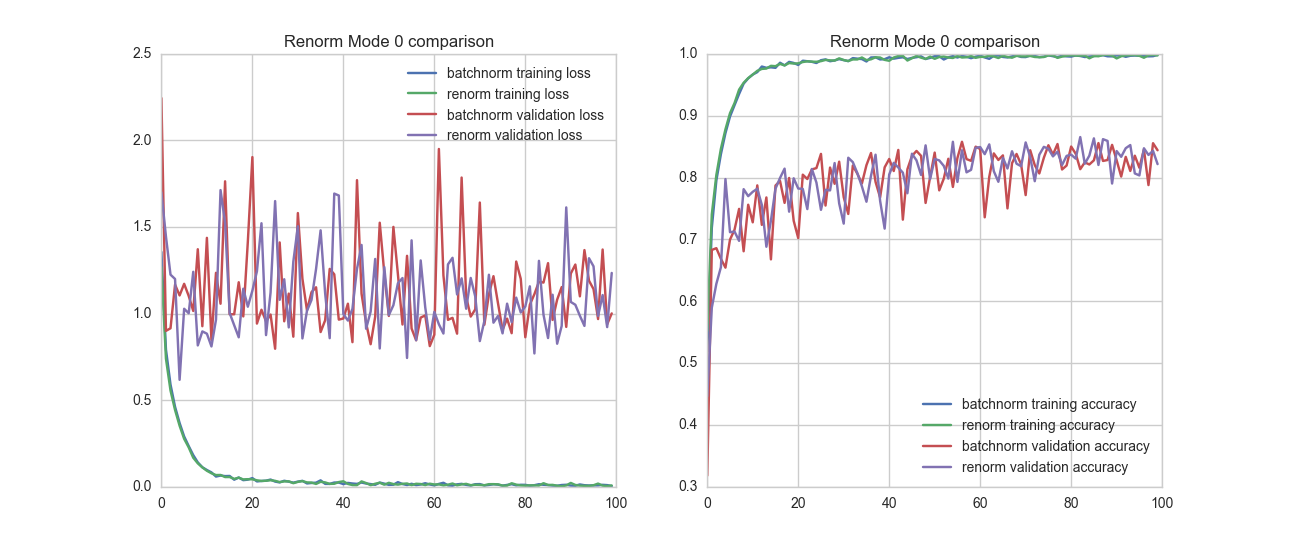
The following graph is from training a Wide Residual Network (WRN-16-4) on the CIFAR 10 dataset, with no data augmentation and no dropout. Therefore all models clearly overfit.
However, the graphs compare WRN-16-4 model with Keras BatchNormalization (mode 0) with BatchRenormalization (mode 0 and mode 2). All other parameters are kept constant.
There are several parameters that are present in addition to the parameters in BatchNormalization layers.
r_max_value: The clipped maximum value that the internal parameter 'r' can take. The value of r will be clipped in the range
(1 / r_max_value, r_max_value) after a sufficient number of iterations.
The paper suggests a default value of 3.
d_max_value: The clipped maximum value that the internal parameter 'd' can take. The value of d will be clipped in the range
(-d_max_value, d_max_value) after a sufficient number of iterations.
The paper suggests a default value of 5.
t_delta: This parameter determines in how many iterations the internal r_max and d_max values will become equal to
r_max_value and d_max_value.
Default setting is 1, which means that in 5 iterations the internal parameters
will become their maximum value.
Values larger than 1 can cause gradient explosion, and prevent learning of anything useful.
Using very small values will lead to slower learning, but eventually will lead to the same result as using
t_delta = 1.
Sugggested t_delta values = 1 to 1e-3.
Keras 1.2.1 (will be updated when Keras 2 launches)
Theano / Tensorflow
h5py
seaborn (optional, for plotting training graph)